如何实现中文命名实体识别
写在前头的话
- 本文来自于taishan1994的GitHub项目BERT-BILSTM-CRF我是跳转链接
先暂时不要git clone repo,因为repo里面有点不全,后面还得下载底模之类的数据
- 本项目还算新的(笔者作这篇文章时还可以成功运行起来 2024-03-14) 而且使用的是pytorch,相比TensorFlow写的不知道好到哪里去了
- 想读懂本文最好有一点的Python基础
如何实现文本识别分类
在实现文本识别分类的过程中,我们通常会遵循以下步骤:
数据预处理:这是任何机器学习项目的第一步。我们需要清洗和格式化我们的原始数据,使其能够被我们的模型接受。在文本分类任务中,这可能包括去除停用词(例如“的”,“和”,“是”等在文本中频繁出现但不携带太多信息的词),进行词干提取(将词汇还原为其基本形式,例如将“running”转换为“run”),或者将我们的文本转换为向量(一种可以被模型接受的数值格式)。
特征选择:在这一步,我们会选择最能代表我们数据的特征。在文本分类任务中,这可能包括词频、TF-IDF值(一种衡量词在文本中的重要性的统计数据),或者词嵌入(一种使用神经网络将词转换为向量的技术)。
模型训练:在这一步,我们会使用我们的预处理数据和选择的特征来训练我们的模型。这可能包括设置模型的参数,选择损失函数和优化器,以及决定训练的轮数。
模型评估:在这一步,我们会使用一些指标(例如准确率、召回率、F1分数等)来评估我们的模型的性能。这可以帮助我们了解我们的模型在未见过的数据上可能的表现,并帮助我们找到可能的改进点。
模型优化:根据我们的模型评估结果,我们可能需要回到前面的步骤进行调整,例如选择不同的特征、改变模型参数,或者尝试不同的模型。
模型部署:一旦我们对我们的模型满意,我们就可以将其部署到实际的系统或产品中。在文本分类任务中,这可能包括将模型嵌入到一个文本编辑器中,或者使用模型来自动标记社交媒体平台上的帖子。
在这里我们只需要进行数据预处理和模型训练以及部署步骤就行了,其他的使用我是跳转链接项目里面的东西即可实现
环境搭建
环境搭建很重要,比重要更重要
Anaconda下载
笔者以Windows 10 Pro 2022H 系统举例
- Anaconda下载
前往我是链接下载Anaconda installer
- 设置系统变量
打开Windows搜索 搜索高级系统设置  选中高级(Advanced) 再点击环境变量(Environment Variables)
选中高级(Advanced) 再点击环境变量(Environment Variables) 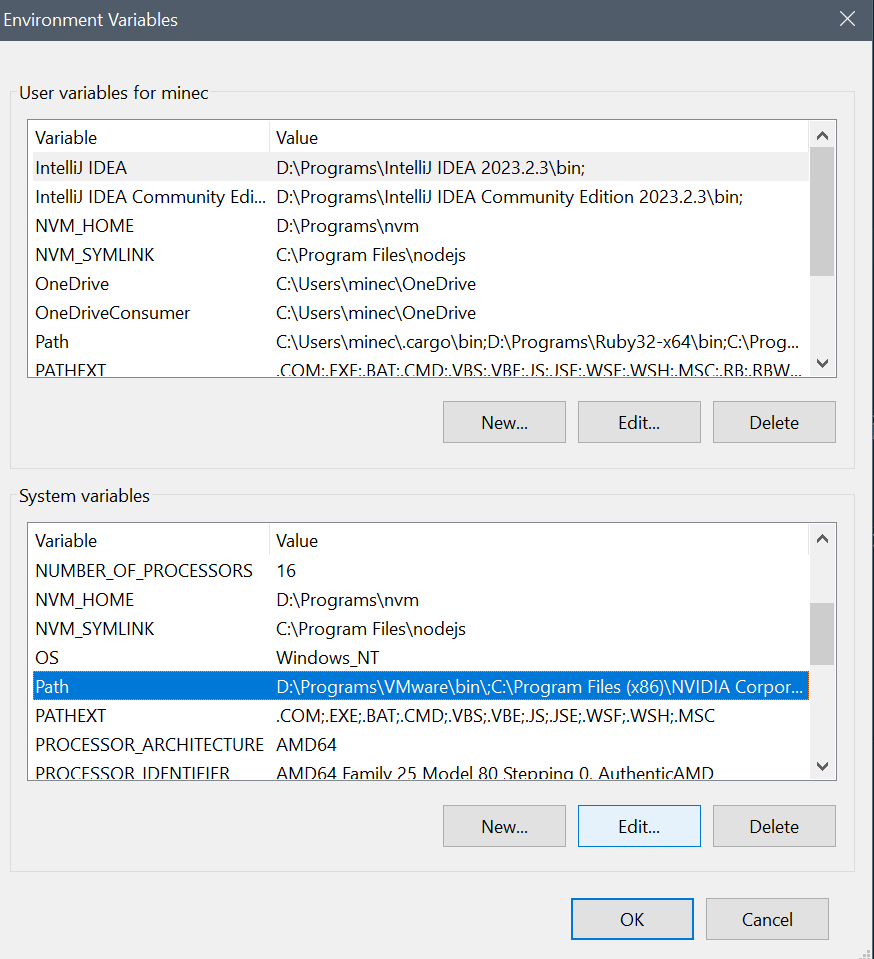 在弹出的界面中 找到系统变量的Path 点击编辑(Edit) 然后再弹出一个界面
在弹出的界面中 找到系统变量的Path 点击编辑(Edit) 然后再弹出一个界面  把刚才安装的Anaconda目录下面的根目录和\Scripts 以及 \Libaray\bin导入进去
把刚才安装的Anaconda目录下面的根目录和\Scripts 以及 \Libaray\bin导入进去  (类似于这样)
(类似于这样)
然后点击ok ok apply即可 
- 验证
打开电脑的cmd或者powershell 输入
1
conda
如果出现像下面这样的东西 即可证明安装成功
1
2
3
4
5
6
7
8
9
usage: conda-script.py [-h] [-V] command ...
conda is a tool for managing and deploying applications, environments and packages.
Options:
positional arguments:
command
.......省略暂且不谈
- 4.创建环境
在cmd或者powershell(powershell可能要额外设置我是解决方案)终端中输入
1
2
conda create -n your_env_name
conda create -n torch //your_env_name 这个自己取为了方便我用自己的环境举例
创建好环境后可以输入
1
conda activate torch(你自己用的时候改为你自己的环境名称)
- 5.构建环境
构建环境永远是最烦的,比烦更烦
项目原作者给出来的环境是像这样的
1
2
3
4
5
scikit-learn==1.1.3
scipy==1.10.1
seqeval==1.2.2
transformers==4.27.4
pytorch-crf==0.7.2
在我自己尝试下载时 发现每次pip install transformers==4.27.4都会报他一共子库的错误,提示我没有rustc开发环境导致那个包死活编译不出来,可是当笔者下了一套rustc后还是失败,遂放弃之 在愤怒过后发现其实可以直接
1
pip install transformers
这样下载出来的transformer比较新(4.38.2),实际上这个项目也是可以用的 然后贴一下我的conda yaml文件
数据预处理
在实现中文命名实体识别的过程中,数据预处理是一个非常重要的步骤。
1. 你应该知道的事情(BIO)
在命名实体识别中,我们通常使用BIO标注体系。B代表实体的开始,I代表实体的中间,O代表非实体。例如,在句子”我在北京上学”中,”北京”是一个地名实体,我们可以将其标注为”B-LOC”。
2. YEDDA使用方法
YEDDA是一个强大的文本标注工具,它支持快速高效的文本标注。你可以使用YEDDA来进行BIO标注。首先,你需要下载并安装YEDDA。然后,你可以创建一个新的标注任务,并开始标注你的文本。 在标注前请先修改你的配置文档
配置文档在YEDDA config文件夹里面 里面默认有一个default.config文件,在首次
1
python yedda.python
之前,请给default.config文件复制一份出一个default copy.config,这个破软件有点bug 然后对这个default copy.config进行修改
1
{"a": "Artifical", "c": "Fin-Concept", "b": "Event", "e": "Organization", "d": "Location", "g": "Sector", "f": "Person", "h": "Other"}
“a”里面表示的是键盘键位
“Artifical”表示的是命名,可以根据自己喜好修改
比如改为
1
{"a": "人物", "b": "书籍", "c": "出版社"}
请注意YEDDA只能导出中文实体类别,无法导出关系,所以YEDDA过时了
3. 导出
在完成标注后,你可以使用YEDDA的export功能,将你的标注结果导出为一个文本文件。这个文件将包含你的原始文本以及对应的BIO标注。 导出选择一定要选择 BIO 不要选择下面的两个东西 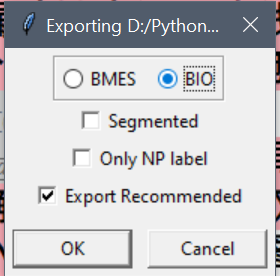
模型训练
1. 底模导入
数据和模型下载地址:https://cowtransfer.com/s/3a155b702dfa42 点击链接查看 [ BERT-BILSTM-CRF ] ,或访问奶牛快传 cowtransfer.com 输入传输口令 hmpdf8 查看; 下载完了后解压到你想要的文件夹里面 然后激活conda 环境
1
conda activate torch
再跑一下predict.py看看之前配的环境行不行
1
python predict.py
出现像下面的文本内容即为成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
文本>>>>>: 潜水艇故障,原因是发动机熄火
实体>>>>>: {'故障设备': [('潜水艇', 0, 2), ('发动机', 9, 11)], '故障原因': [('故障', 3, 4), ('熄火', 12, 13)]}
====================================================================================================
文本>>>>>: 492号汽车故障报告故障现象一辆车用户用水清洗发动机后,在正常行驶时突然产生铛铛异响,自行熄火
实体>>>>>: {'故障原因': [('异响', 40, 41), ('熄火', 45, 46)]}
====================================================================================================
文本>>>>>: 故障现象:空调制冷效果差。
实体>>>>>: {'故障设备': [('空调', 5, 6)], '故障原因': [('制冷效果差', 7, 11)]}
====================================================================================================
文本>>>>>: 原因分析:1、遥控器失效或数据丢失;2、ISU模块功能失效或工作不良;3、系统信号有干扰导致。处理方法、体会:1、检查该车发现,两把遥控器都不能工作,两把遥控
器同时出现故障的可能几乎是不存在的,由此可以排除遥控器本身的故障。2、检查ISU的功能,受其控制的部分全部工作正常,排除了ISU系统出现故障的可能。3、怀疑是遥控器数
据丢失,用诊断仪对系统进行重新匹配,发现遥控器匹配不能正常进行。此时拔掉ISU模块上的电源插头,使系统强制恢复出厂设置,再插上插头,发现系统恢复,可以进行遥控操
作。但当车辆发动在熄火后,遥控又再次失效。4、查看线路图发现,在点火开关处安装有一钥匙行程开关,当钥匙插入在点火开关内,处于ON位时,该开关接通,向ISU发送一个信
号,此时遥控器不能进行控制工作。当钥匙处于OFF位时,开关断开,遥控器恢复工作,可以对门锁进行控制。如果此开关出现故障,也会导致遥控器不能正常工作。同时该行程开
关也控制天窗的自动回位功能。测试天窗发现不能自动回位。确认该开关出现故障
实体>>>>>: {'故障设备': [('遥控器', 7, 9), ('ISU模块', 20, 24), ('系统信号', 37, 40), ('遥控器', 66, 68), ('遥控器', 158, 160), ('遥控器', 182, 184), ('开关', 434, 435)], '故障原因': [('失效', 10, 11), ('数据', 13, 14), ('丢失', 15, 16), ('功能失效', 25, 28), ('工作不良', 30, 33), ('干扰', 42, 43), ('不能工作', 70, 73), ('数据丢失', 161, 164), ('失效', 260, 261), ('不能自动回位', 424, 429), ('故障', 438, 439)]}
====================================================================================================
文本>>>>>: 原因分析:1、发动机点火系统不良;2、发动机系统油压不足;3、喷嘴故障;4、发动机缸压不足;5、水温传感器故障。
实体>>>>>: {'故障设备': [('发动机点火系统', 7, 13), ('发动机系统', 19, 23), ('喷嘴', 31, 32), ('发动机', 38, 40), ('水温传感器', 48, 52)], '故障原因': [('不良
', 14, 15), ('油压不足', 24, 27), ('故障', 33, 34), ('缸压不足', 41, 44), ('故障', 53, 54)]}
====================================================================================================
2. ner_data处理
将之前YEDDA导出的bio文件放到刚才解压缩完的文件夹里面 然后对bio文件进行预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import os
def bio_to_dicts(filename):
with open(filename, 'r') as f:
lines = f.readlines()
data = []
text = []
labels = []
for line in lines:
line = line.strip()
if line: # 如果行不为空
parts = line.split(' ')
if len(parts) == 2: # 如果这一行有两个部分,那么我们可以解包为word和label
word, label = parts
text.append(word)
labels.append(label)
else: # 如果行为空,表示一个实体的结束
if text and labels: # 如果text和labels不为空
data.append({"text": text, "labels": labels, "id": len(data)})
text = []
labels = []
# 添加最后一个实体
if text and labels:
data.append({"text": text, "labels": labels, "id": len(data)})
return data
def write_to_file(data, filename):
with open(filename, 'w') as f:
for item in data:
f.write(str(item) + '\n')
data = bio_to_dicts('a.txt.bio') #改为你的文件名
write_to_file(data, 'train.txt')
然后上面这个脚本文件(保存下来命名为dict.py)
1
python dict.py
然后根文件夹里面应该就有一个train.txt文件 其格式应该是这样的
1
2
{"id": "AT0001", "text": ["6", "2", "号", "汽", "车", "故", "障", "报", "告", "综", "合", "情", "况", ":", "故", "障", "现", "象", ":", "加", "速", "后", ",", "丢", "开", "油", "门", ",", "发", "动", "机", "熄", "火", "。"], "labels": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-故障设备", "I-故障设备", "I-故障设备", "B-故障原因", "I-故障原因", "O"]}
{"id": "AT0002", "text": ["4", "9", "2", "号", "汽", "车", "故", "障", "报", "告", "故", "障", "现", "象", "一", "辆", "车", "用", "户", "用", "水", "清", "洗", "发", "动", "机", "后", ",", "在", "正", "常", "行", "驶", "时", "突", "然", "产", "生", "铛", "铛", "异", "响", ",", "自", "行", "熄", "火"], "labels": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-故障设备", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-故障原因", "I-故障原因", "O", "O", "O", "B-故障原因", "I-故障原因"]}
这个文件有很多行,然后根据文件目录,在data下面新建一个文件夹,比如新建一个fish,fish下面再新建一个ner_data文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
--checkpoint:模型和配置保存位置
--model_hub:预训练模型
----chinese-bert-wwm-ext:
--------vocab.txt
--------pytorch_model.bin
--------config.json
--data:存放数据
----dgre
--------ori_data:原始的数据
--------ner_data:处理之后的数据
------------labels.txt:标签
------------train.txt:训练数据
------------dev.txt:测试数据
----fish:新建文件
--------ori_data:我们不需要,因为数据我明明已经处理好了
--------ner_data:处理之后的数据
--------------空
--config.py:配置
--model.py:模型
--process.py:处理ori数据得到ner数据
--predict.py:加载训练好的模型进行预测
--main.py:训练和测试
再把刚才的train.txt放进去
然后新建两个txt文件,命名为label.txt,dev.txt ,此时文件夹应该像这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
--checkpoint:模型和配置保存位置
--model_hub:预训练模型
----chinese-bert-wwm-ext:
--------vocab.txt
--------pytorch_model.bin
--------config.json
--data:存放数据
----dgre
--------ori_data:原始的数据
--------ner_data:处理之后的数据
------------labels.txt:标签
------------train.txt:训练数据
------------dev.txt:测试数据
----fish:新建文件
--------ori_data:我们不需要,因为数据我明明已经处理好了
--------ner_data:处理之后的数据
------------labels.txt:标签
------------train.txt:训练数据
------------dev.txt:测试数据
--config.py:配置
--model.py:模型
--process.py:处理ori数据得到ner数据
--predict.py:加载训练好的模型进行预测
--main.py:训练和测试
然后给label.txt里面输入你刚才yedda配置文件里面的东西 配置文件
1
{"a": "人物", "b": "书籍", "c": "出版社"}
label.txt
1
2
3
人物
书籍
出版社
3. 修改config
在config.py里面定义一些参数,比如: –max_seq_len:句子最大长度,GPU显存不够则调小。 –epochs:训练的epoch数 –train_batch_size:训练的batchsize大小,GPU显存不够则调小。 –dev_batch_size:验证的batchsize大小,GPU显存不够则调小。 –save_step:多少step保存模型 其余的可保持不变。
4. 开始训练
在main.py里面修改data_name为数据集名称。需要注意的是名称和data下的数据集名称保持一致。
1
2
3
188 if __name__ == "__main__":
189 data_name = "fish" //之前是dgre,现在改为fish,请根据需要修改
190 main(data_name)
最后运行:
1
python main.py
模型预测/模型评估
在predict.py修改data_name并加入预测数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
if __name__ == "__main__":
data_name = "fish" #修改为你自己的训练集的名字
predictor = Predictor(data_name)
if data_name == "dgre":
texts = [
"潜水艇故障,原因是发动机熄火",
"492号汽车故障报告故障现象一辆车用户用水清洗发动机后,在正常行驶时突然产生铛铛异响,自行熄火",
"故障现象:空调制冷效果差。",
"原因分析:1、遥控器失效或数据丢失;2、ISU模块功能失效或工作不良;3、系统信号有干扰导致。处理方法、体会:1、检查该车发现,两把遥控器都不能工作,两把遥控器同时出现故障的可能几乎是不存在的,由此可以排除遥控器本身的故障。2、检查ISU的功能,受其控制的部分全部工作正常,排除了ISU系统出现故障的可能。3、怀疑是遥控器数据丢失,用诊断仪对系统进行重新匹配,发现遥控器匹配不能正常进行。此时拔掉ISU模块上的电源插头,使系统强制恢复出厂设置,再插上插头,发现系统恢复,可以进行遥控操作。但当车辆发动在熄火后,遥控又再次失效。4、查看线路图发现,在点火开关处安装有一钥匙行程开关,当钥匙插入在点火开关内,处于ON位时,该开关接通,向ISU发送一个信号,此时遥控器不能进行控制工作。当钥匙处于OFF位时,开关断开,遥控器恢复工作,可以对门锁进行控制。如果此开关出现故障,也会导致遥控器不能正常工作。同时该行程开关也控制天窗的自动回位功能。测试天窗发现不能自动回位。确认该开关出现故障",
"原因分析:1、发动机点火系统不良;2、发动机系统油压不足;3、喷嘴故障;4、发动机缸压不足;5、水温传感器故障。",
]
elif data_name == "duie":
texts = [
"歌曲《墨写你的美》是由歌手冷漠演唱的一首歌曲",
"982年,阎维文回到山西,隆重地迎娶了刘卫星",
"王皃姁为还是太子的刘启生了二个儿子,刘越(汉景帝第11子)、刘寄(汉景帝第12子)",
"数据分析方法五种》是2011年格致出版社出版的图书,作者是尤恩·苏尔李",
"视剧《不可磨灭》是导演潘培成执导,刘蓓、丁志诚、李洪涛、丁海峰、雷娟、刘赫男等联袂主演",
]
elif data_name == "fish":#新增一条判断语句读入texts 仿照上面写就行了
texts = [
"114514",
"1919810",
]
最后运行:
1
python predict.py
等待戈多
常见问题
- 1.CUDA
在运行predict.py提醒没有GPU而是使用CPU,建议去下个pytorch cuda 我是链接
- 2.python软件包不匹配
TypeError: init() got an unexpected keyword argument ‘batch_first’: pip install pytorch-crf==0.7.2
1
pip install pytorch-crf==0.7.2
然后其他pip install时还出问题可以看我环境搭建时上面提供的torch.yaml文件,直接下载了给conda用一份就可以
- 3.训练自己数据集时python main.py时提醒train.txt或者dev.txt有空格
把
1
2
3
4
149 train_data = [json.loads(d) for d in train_data]
153 dev_data = [json.loads(d) for d in dev_data]
改成
1
2
3
4
149 train_data = [json.loads(d.replace("'", '"')) for d in train_data if d.strip()]
153 dev_data = [json.loads(d.replace("'", '"')) for d in dev_data if d.strip()]
解释: train_data 和 dev_data 是包含字符串的列表。每个字符串应该是一个 JSON 对象的字符串表示形式。
d.replace(“’”, ‘”’):这部分代码将字符串中的单引号(’)替换为双引号(”)。这是因为在 JSON 标准中,所有的字符串都必须用双引号括起来。如果原始数据使用了单引号,那么这个替换操作就是必需的。
json.loads(d.replace(“’”, ‘”’)):这部分代码将替换后的字符串转换为 Python 的字典或列表。json.loads() 是一个将 JSON 字符串转换为 Python 对象的函数。
[json.loads(d.replace(“’”, ‘”’)) for d in train_data if d.strip()]:这部分代码是一个列表推导式,它遍历 train_data 中的每个元素 d,如果 d 不是空字符串(d.strip() 的结果不是空字符串),那么就将 d 转换为 Python 对象并添加到新的列表中。
最后,这个新的列表被赋值给 train_data 和 dev_data,替换了原来的数据。
- 4.其他问题 邮件给我cuvo@foxmail.com (qq邮箱可能一两天看一次)