BERT
既生BERT,何生LLM?
本文稍微研究了一下BERT的论文,从现在的角度去看BERT,也许很简陋,各种方面都被LLM打爆,但这个作为Transformer应用的经典案例,不可不读
论文地址
Pre-training of Deep Bidirectional Transformers for Language Understanding
用于语言理解的深度双向转换器的预训练
在学习之前,首先需要了解一下注意力机制,注意力机制首先出现在一篇名为Attention is all you need的论文上 这篇论文提出了一种名为Attention的全新机制,比较以往的RNN要更加先进 大致模块运行如下
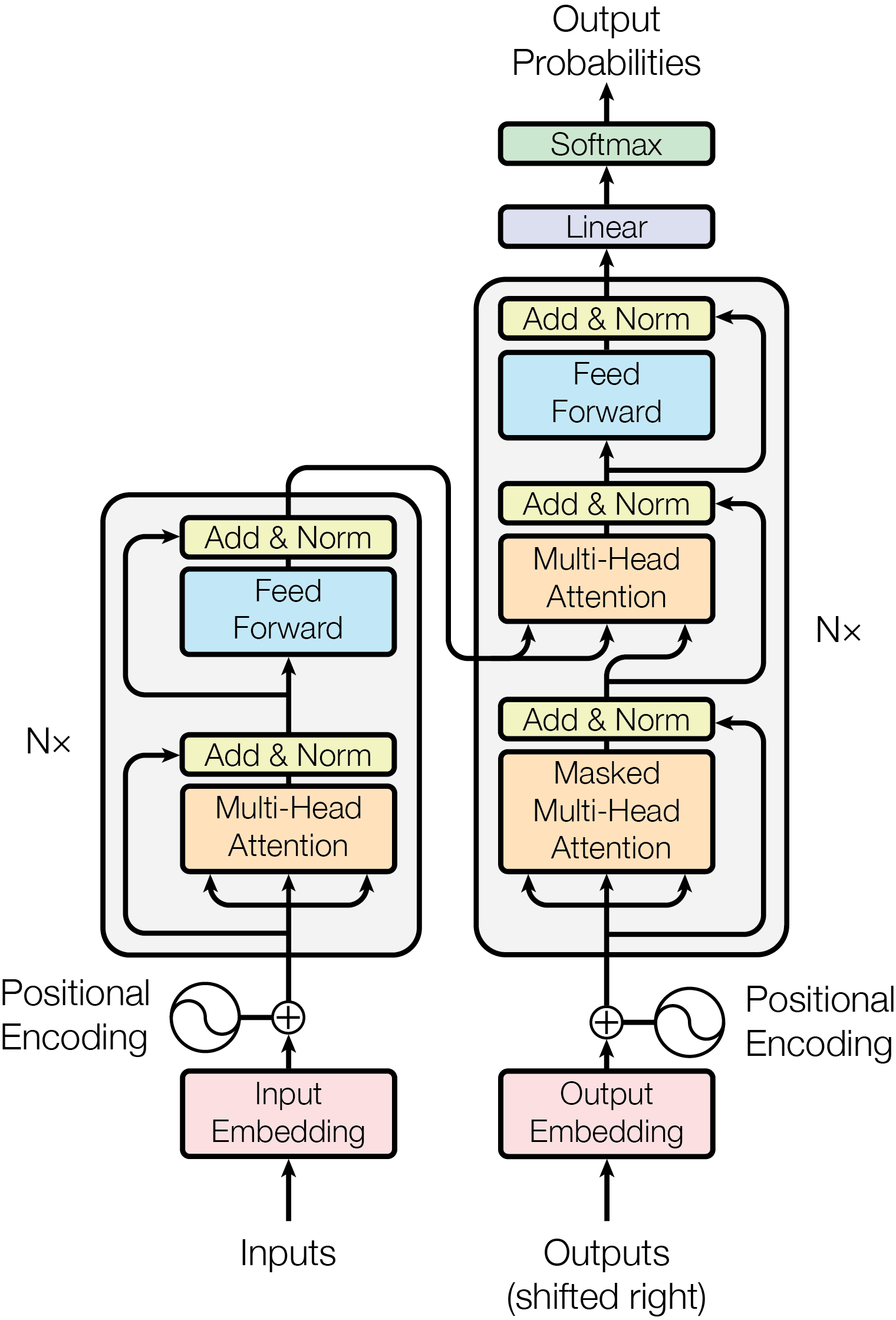
为了方便理解,可以借助一些可视化项目了解: dodrio
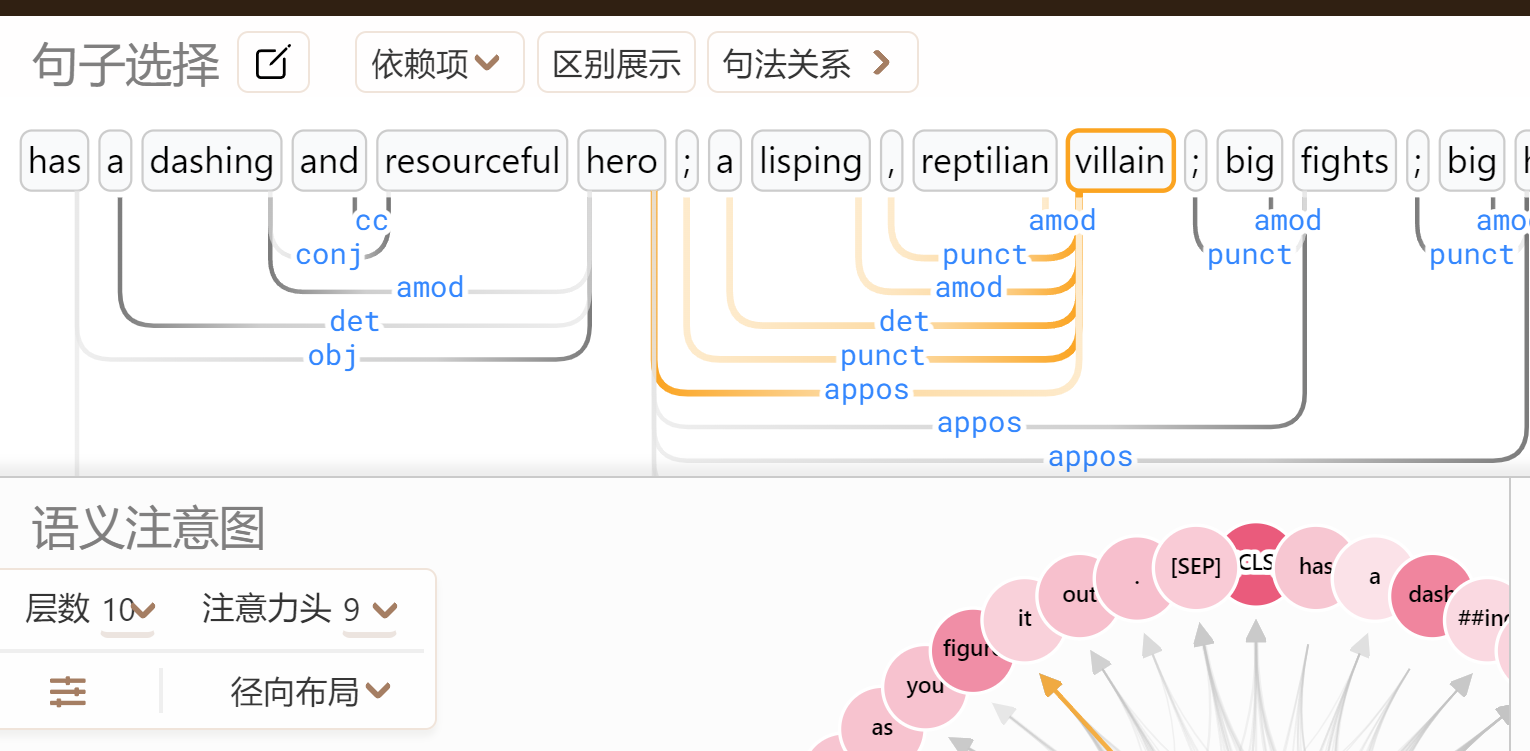 比方说这里的villain单词和之前的5个单词有着各自不同的关系的link
比方说这里的villain单词和之前的5个单词有着各自不同的关系的link
本文由作者按照 CC BY 4.0 进行授权